10.1 样本相关数据重处理
在使用EasyMultiProfiler包进行数据分析时,不可避免的需要对样本相关数据进行重新分组等操作。此时,无需修改原始数据并重新组装MAE对象,而是可以利用MAE对象的$方法和tidy语法来处理样本相关数据。
10.1.1 样本相关数据重分组
🏷️示例:
从原始MAE对象中提取组学项目taxonomy的coldata,将coldata中原始的表型变量Education_Years衍生为新的表型变量Edu_status(以新的表型变量作为分组信息),再利用MAE对象的$ 方法将新的表型变量加入原始MAE对象。
注意:
新的coldata与原始的coldata的
新的coldata与原始的coldata的
primary列的受试者编号排序必须完全一致。
raw_meta <- MAE|>
EMP_coldata_extract(experiment = 'taxonomy')
new_meta <- raw_meta |>
dplyr::mutate(Edu_status = dplyr::if_else(Education_Years > 15, "High", "Low"))
new_meta <- new_meta[match(raw_meta$primary, new_meta$primary), ]
MAE$Edu_status <- new_meta$Edu_status
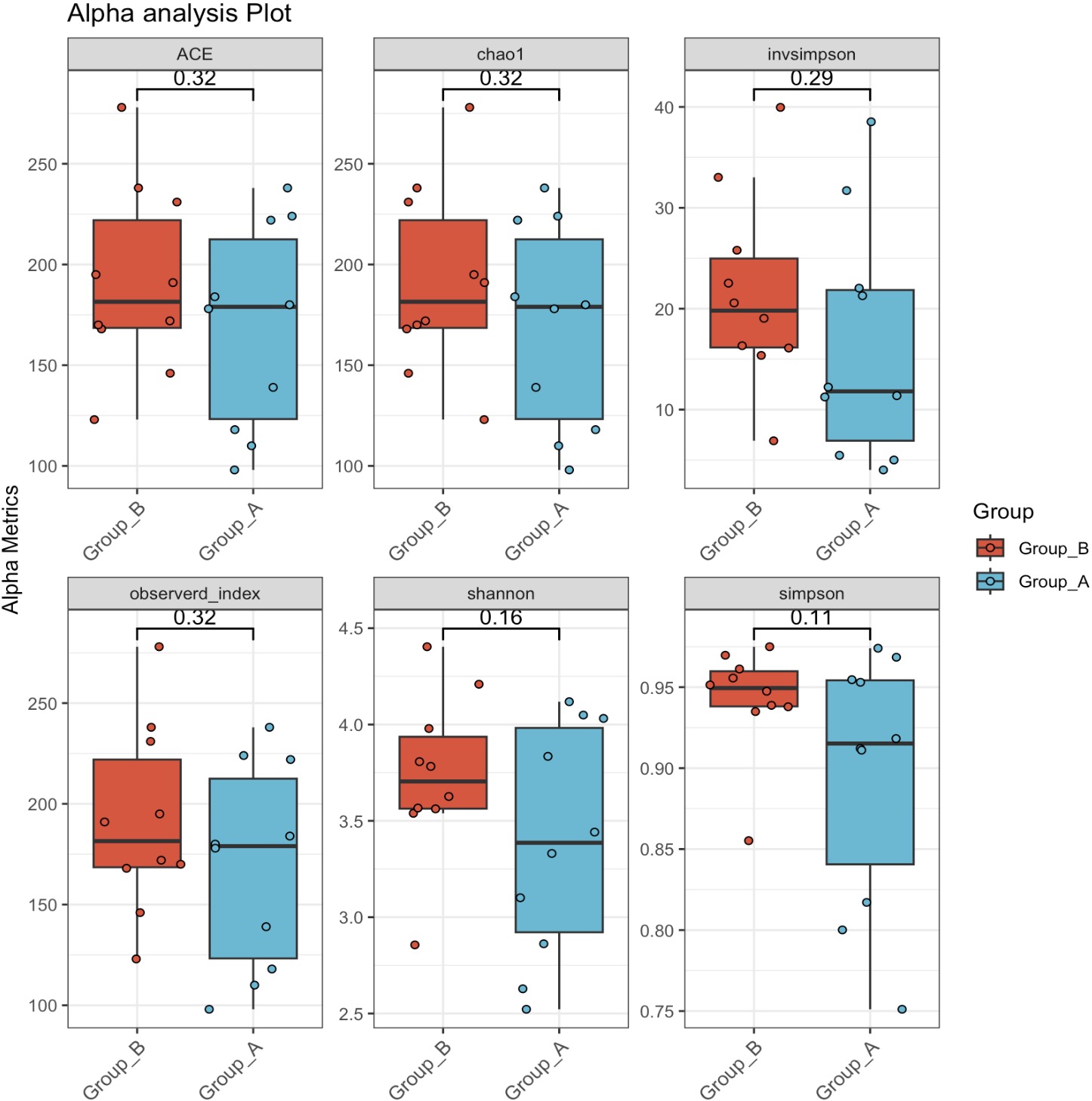
10.1.2 样本相关数据的因子排序
在可视化过程中,有时候需要对样本相关数据内的分组进行重排序,以满足绘图需求。
🏷️示例:利用MAE的$方法对原始分组进行因子排序。
MAE$Group <- factor(MAE$Group, levels = c('Group_B','Group_A'))
MAE |>
EMP_assay_extract(experiment='taxonomy') |>
EMP_alpha_analysis() |>
EMP_boxplot(estimate_group='Group',method='t.test')